
Text Classification using OpenAI's GPT-3: Embeddings, Zero-shot learning, and Fine-tuning
I create various machine learning models using OpenAI's GPT-3 to predict the category of UK public company filings.

Background:
Public companies submit all sorts of filings to regulators. We want to classify filings by their type. The most well known type is Financials (think quarterly or annual earnings reports), but there are also proxies, share transactions, prospectuses, and others. Here’s an example of some of Rolls-Royce’s filings:

Around 5% of filings are submitted without a category due to user error. I will walk you through various techniques to guess the category.
Results Overview:
Approach 1: OpenAI Embedding + Scikit-Learn Random Forest Model
Text embedding is the process of mapping a sequence of text to a dense vector of numbers, such that semantically similar words are mapped to close vectors. We can use these embeddings as features in a machine learning model.
Use the document name to predict the category.
Example: Function(“2022 Half Year Results”) → “Financials”
More specifically:
RandomForestClassifier(OpenAIEmbedding(“2022 Half Year Results”)) → “Financials”
OpenAI has an embedding API (Embedding API Docs) and Scikit-Learn has a random forest classification implementation (Scikit Random Forest Docs).
First, I cluster various categories together to make more general categories like “Financials”. You can see there are 19580 filings without a category out of 459,433.

Since OpenAI APIs rate limit you to around 1000/min, I will only calculate the embedding vectors for 10,000 random filing names.

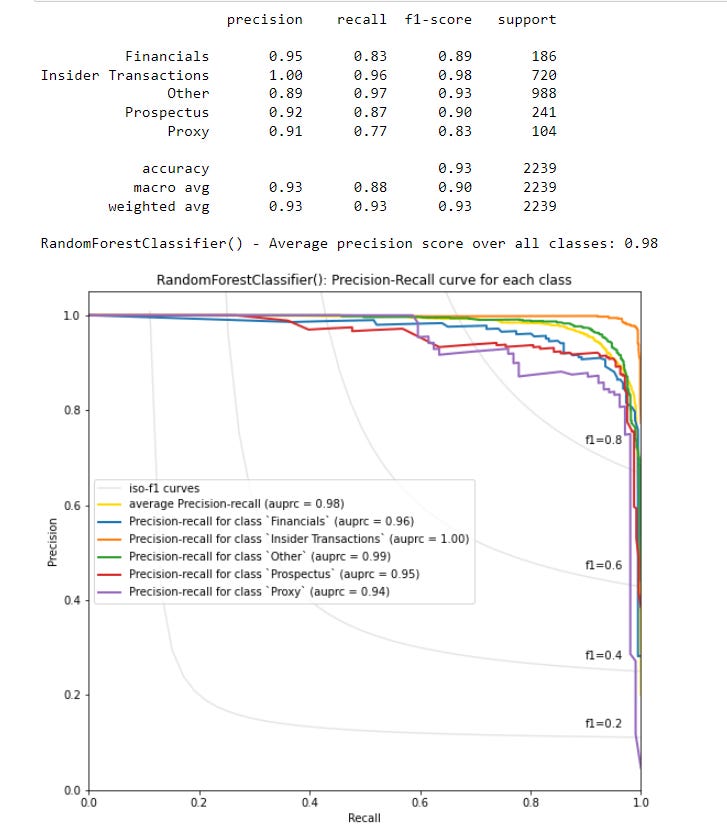
Now that I have my embedding vectors, I create a training and test set. Then apply the Random Forest Classifier and display the results.

You can see it performs quite well on all the categories except “Prospectus”. Why?

There aren’t enough Prospectus samples to train an appropriate classifier. There are 1100 “Prospectus” samples in the dataset so let’s add them all to achieve a much better result. This model accurately identifies the filing category 93% of the time.
Approach 2: Embrace the magic of GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is an advanced language processing AI model developed by OpenAI, with over 175 billion parameters. GPT-3 is trained on a massive amount of diverse text data from the internet and is capable of many things, including text categorization.
Let’s see how GPT-3 does when we simply ask it to classify the documents with no training. Let’s ask it for the category of 1000 filings.
Here’s our prompt:
Classify the following UK public company filings type by using there name. Choose one of these categories "Financials", "Insider Transactions", "Prospectus", "Proxy", "Other".
[Filing Name] : [Category]

It does surprisingly well! It is correct 72.9% of the time. While this isn’t as good as our first approach (Embedding + Random Forest Model),This is all with no model training.

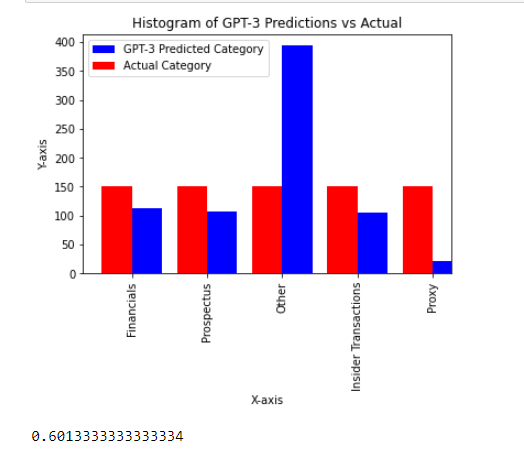
I also grabbed samples randomly and some filing types are less common than others. Let’s see how GPT-3 does when we ask it about 150 of each filing type. The accuracy decreases to 60% and we can see a lot of the issue is with identifying filings of the “Proxy” category.
Approach 3: Fine-tuning GPT-3
While the out-of-the-box GPT-3 is able to predict filing categories at a 73% accuracy, let’s try fine-tuning our own GPT-3 model. Fine-tuning a large language model involves training a pre-trained model on a smaller, task-specific dataset, while keeping the pre-trained parameters fixed and only updating the final layers of the model.
Simply put, we feed GPT-3 a bunch of training examples of our document names and filings and then see how it performs on a test set.
I use a set of 3,500 examples, with 700 cases of each classification type.

OpenAI has some great command line utilities to help this process: automatically formatting the prompts, splitting into training vs validation, and removing duplicates. See more here for a step-by-step procedure: Fine-tuning example
Here are the results running on our validation set. We eventually achieve an accuracy of 89.4%. One could keep adding training samples to try and get the accuracy higher but this demonstrates the power.

This is similar to my first approach (Embeddings + Random Forest) which yielded a 93% accuracy.
Conclusion
In conclusion, OpenAI’s GPT-3 is a powerful tool. Without knowing much about machine learning algorithms, one could create powerfully accurate classification predictions by throwing a relatively small amount of examples at fine-tuning GPT-3. Going through and manually labelling a couple thousand samples is something many companies and individuals have the capacity to do.